Project: Fiscal data classification
Problem: The client is a major player on the Fiscal data market and has to process~100 million receipts each day. The client was limited in providing additional services based on the data because names of goods could differ in receipts for the same position (like “beer XYZ”, “beer XYZ 0.5”). Thus, he needed to map similar goods names to the dictionary in the system. This is a real time, high load environment that requires constant adaptation.
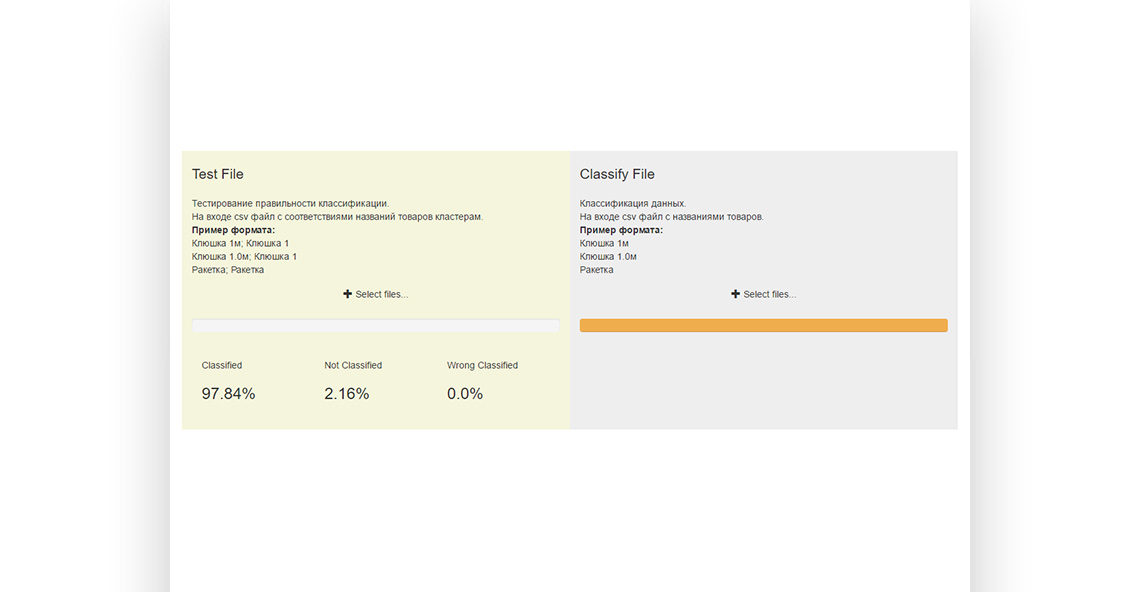
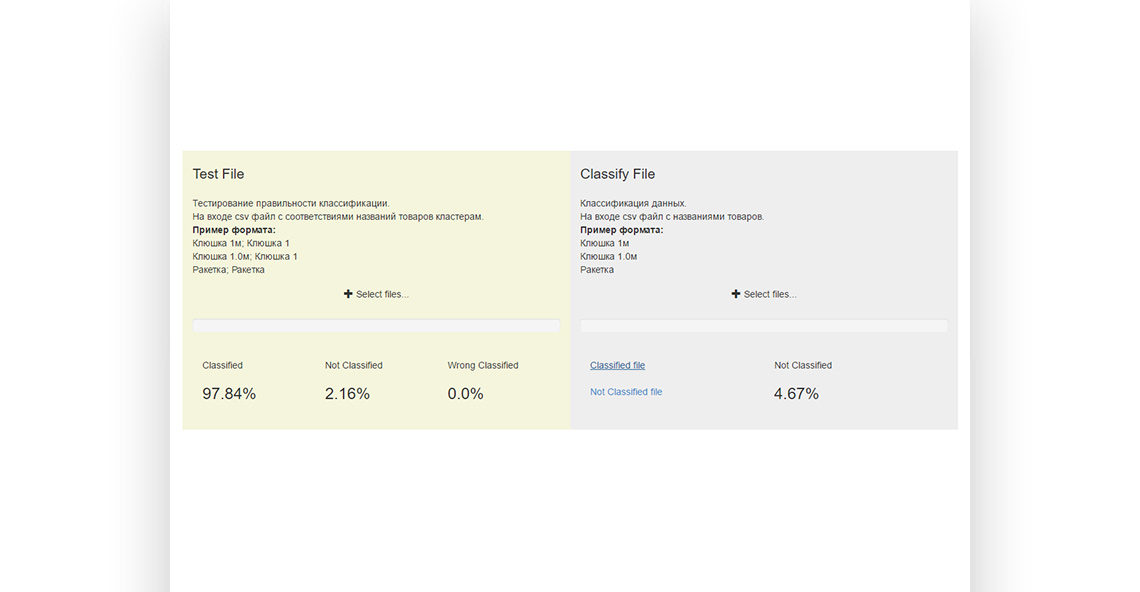
Solution: Use a test data set (several millions of receipts) and create a clustering system first (=master data, unique names).
Then create a custom filter to match the original product name to the name presented in the master data set.
Apply a Machine Learning driven solution in respect to the estimated receipts data flow (=real time, high-load).
Outcome:
- The client was involved throughout at periodic demonstrations and refinements to meet their exact criteria
- The client received proof that fiscal data classification problem is solved
- Integration of such a module into the current software package will allow the client to provide new services based on these normalized data
Technological stack: Python 3.6, Bootstrap, Django.