Проект: Классификация фискальных данных
Проблема: Клиент — основной игрок на рынке фискальных данных, который строго регулируется Федеральной Налоговой Службой. У клиента есть решение, обрабатывающее ~100 млн денежных поступлений ежедневно в режиме реального времени. Система способна хранить несколько петабайтов исходных данных. Клиент не мог оказывать дополнительные услуги, так как наименование одного и того же товара могло не совпадать с наименованием, указанным в чеках (например, «пиво XYZ», «пиво XYZ 0.5»). Таким образом, клиенту требовалось создавать уникальный артикул похожим товарам и вносить их в справочник системы.
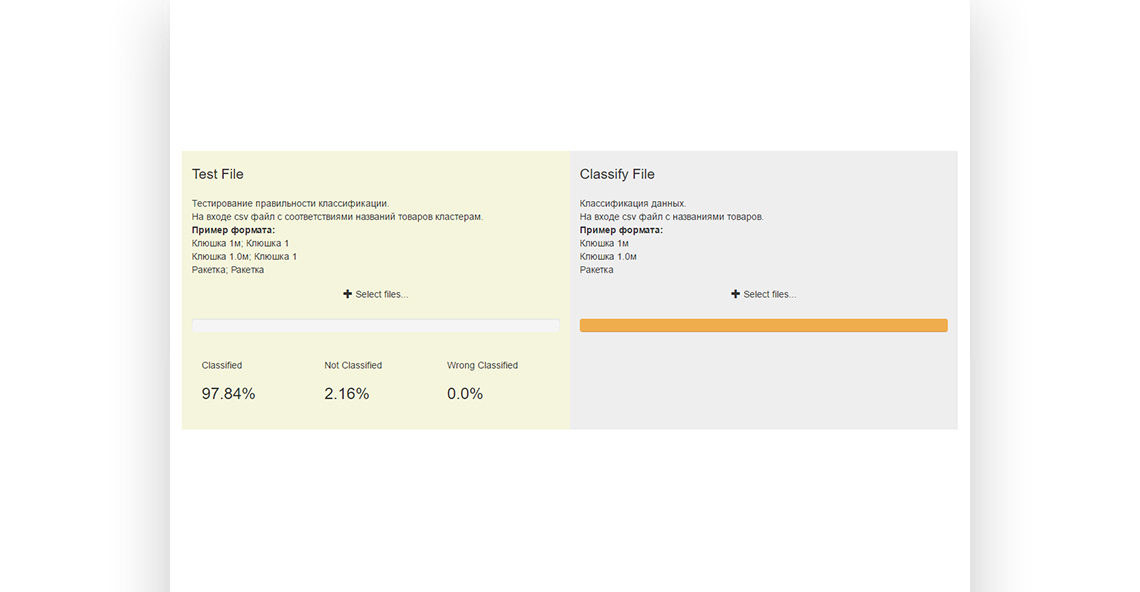
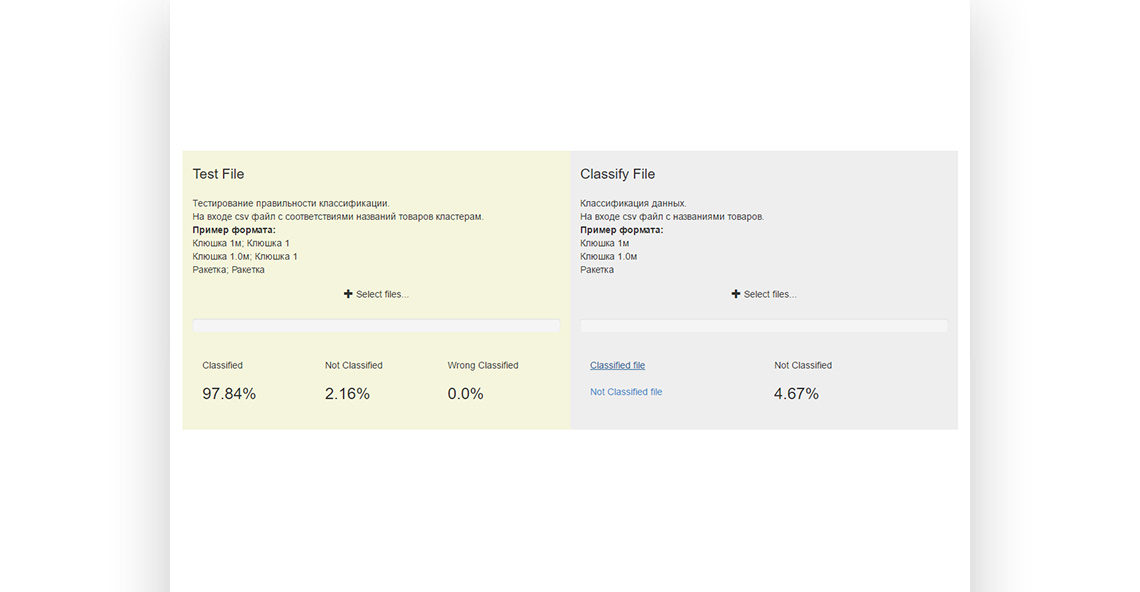
Решение: Мы получили тестируемый набор данных (данные, взятые из нескольких миллионов чеков) и создали в начале систему кластеризации (=основные данные, уникальные имена). Затем мы сделали фильтр, который по заданным параметрам соединяет первоначальное наименование с представленным. Было разработано решение на основе машинного обучения применительно к вычисляемому потоку поступающих данных (=режим реального времени, высокая нагрузка). Результаты были представлены клиенту в течение нескольких демо-сессий.
Результат: Клиент получил доказательство того, что проблема классификации наименований товаров решаема. Интеграция такого модуля в текущий программный комплекс позволит клиенту оказывать новые услуги, основанные на этих нормализованных данных.
Технологии: Python 3.6, Bootstrap, Django.